Usando o Falco para monitorar o tráfego de Pods no Kubernetes
Overview
Usando o Falco para monitorar o tráfego de Pods no Kubernetes
O Falco é um projeto opensource da Sysdig para segurança de ambientes Cloud Native, que utiliza-se de tecnologias modernas como eBPF para monitorar situações no ambiente através de syscalls e outros geradores de eventos
Nós já usamos o Falco a algum tempo atrás no trabalho como uma PoC para monitorar alguns eventos específicos, e recentemente eu comecei a mexer com o para ajudar a contribuir a pedido do grande Dan Pop e também para entender melhor como o Falco poderia me ajudar em situações futuras (bem como entender o seu funcionamento).
O Problema que eu queria resolver
Quem mexe com Kubernetes sabe o quão difícil é manter o rastreio de conexões originadas de seus Pods. Mesmo que você coloque Network Policies, é muito difícil monitorar que Pod tentou abrir uma conexão para o mundo exterior.
Ter esse tipo de informação é fundamental em ambientes com um nível de restrição maior, ou que você precise rapidamente responder ‘qual Pod conectou-se a esse outro servidor’, inclusive por motivos legais.
Alguns CNIs provêm uma solução, como o Antrea exportando o fluxo de dados via Netflow, ou o Cilium com uma solução de curta retenção através do seu projeto Hubble.
Mas eu queria algo mais: Eu queria uma solução que se aplique a qualquer CNI. Se a conexão é dropada ou não, não me importa, mas como toda conexão originada de um container gera uma syscall de conexão, como eu poderia monitorar isso e cruzar com as informações do Kubernetes?
O resultado final
Te apresento o Falco!
Conforme expliquei anteriormente, o Falco é um projeto Opensource que monitora eventos no servidor (que podem ser eventos de auditoria do Kubernetes, ou até syscalls de containers executando em um host).
O Falco é baseado em regras. Essas regras definem principalmente:
- um nome comum (
rule) - “Acesso indevido via SSH” - uma descrição (
desc) - “Um usuário tentou efetuar um login via SSH no servidor” - uma prioridade (
priority) - “WARNING” - Uma saída detalhada do evento (
output) - “O servidor ‘homer’ recebeu uma conexão na porta 22 vinda do IP não autorizado 192.168.0.123” - uma CONDIÇÃO (
cond) - “(O servidor tiver no seu hostname a palavra ‘restrito’ e receber uma conexão na porta 22 que não venha da rede 10.10.10.0/24) OU (O servidor recebeu uma conexão na porta 22 mas o processo que abriu essa conexão não se chama ‘sshd’)”
Aqui cabe uma observação: Eu escrevi a condição de uma forma ‘simples’ em linguagem comum. Apesar de as regras do Falco não serem escritas dessa forma (veremos mais adiante), o formato é muito ‘similar’ tornando a leitura das regras bem tranquila!
As regras podem conter também outros campos não explicados aqui (exceções, tags adicionais, etc) bem como Listas e Macros que facilitam quando alguma condição é repetitiva (irei mostrar adiante).
Instalando o Falco
Antes de começar a instalar o Falco, apenas uma descrição de meu ambiente:
- 3 servidores virtuais com o Flatcar Linux 2765.2.2, porque EU GOSTO MUITO DO MODELO DO FLATCAR!! (fora que ele já tem um Kernel mais moderno e usar o Falco no modo eBPF simplesmente funciona!!). Se você quiser aprender a instalar o Flatcar em 5 minutos no VMware Player, tem um outro artigo explicando aqui no blog.
- Meus servidores e minha rede aqui em casa são
192.168.0.0/24 - Meu Kubernetes é o v1.21.0, instalado via Kubeadm. Os pods são criados na rede
172.16.0.0/16
Para instalar o Falco no Kubernetes usando o helm, basicamente são 4 passos (claro que você pode alterar, eu segui assim para demonstrar aqui):
1kubectl create ns falco # Eu quero rodar em outro namespace
2helm repo add falcosecurity https://falcosecurity.github.io/charts
3helm repo update
4helm install falco falcosecurity/falco --namespace falco --set falcosidekick.enabled=true --set falcosidekick.webui.enabled=true --set ebpf.enabled=true
Após isso, basta verificar se todos os Pods no namespace falco estão executando com kubectl get pods -n falco
Na instalação acima, eu habilitei também o sidekick que é um projeto bem maneiro para exportar os eventos do Falco (usarei para exportar para um Elasticsearch), bem como visualizar esses eventos em sua própria UI.
Gerando alertas e visualizando
O Falco vem com algumas regras por padrão. Por exemplo, à partir do momento que ele está em execução, se você tentar dar um kubectl exec -it em um Pod, ele irá gerar um alerta:
1kubectl exec -it -n testkatz nginx-6799fc88d8-996gz -- /bin/bash
2root@nginx-6799fc88d8-996gz:/#
E nos logs do Falco (eu dei uma melhorada nesse JSON!):
1{
2 "output":"14:23:15.139384666: Notice A shell was spawned in a container with an attached terminal (user=root user_loginuid=-1 k8s.ns=testkatz k8s.pod=nginx-6799fc88d8-996gz container=3db00b476ee2 shell=bash parent=runc cmdline=bash terminal=34816 container_id=3db00b476ee2 image=nginx) k8s.ns=testkatz k8s.pod=nginx-6799fc88d8-996gz container=3db00b476ee2",
3 "priority":"Notice",
4 "rule":"Terminal shell in container",
5 "time":"2021-04-16T14:23:15.139384666Z",
6 "output_fields": {
7 "container.id":"3db00b476ee2",
8 "container.image.repository":"nginx",
9 "evt.time":1618582995139384666,
10 "k8s.ns.name":"testkatz",
11 "k8s.pod.name":"nginx-6799fc88d8-996gz",
12 "proc.cmdline":"bash",
13 "proc.name":"bash",
14 "proc.pname":"runc",
15 "proc.tty":34816,
16 "user.loginuid":-1,
17 "user.name":"root"
18 }
19}
Você pode ver nesse log, por exemplo que além da mensagem no output, alguns campos adicionais foram mapeados (como o nome do processo, a namespace, o nome do Pod). Iremos explorar mais isso à seguir.
Criando regras para o Falco
Como eu falei, o Falco consegue monitorar as chamadas em syscall. Uma syscall de conexão de rede é do tipo ‘connect’, e sendo assim, podemos criar uma regra básica para o Falco que sempre gere uma notificação quando algum container tentar conectar-se a algum ativo externo a ele.
O Falco vem com uma macro e uma lista pré definida para conexões que saiam de rede assim:
1# RFC1918 addresses were assigned for private network usage
2- list: rfc_1918_addresses
3 items: ['"10.0.0.0/8"', '"172.16.0.0/12"', '"192.168.0.0/16"']
4
5- macro: outbound
6 condition: >
7 (((evt.type = connect and evt.dir=<) or
8 (evt.type in (sendto,sendmsg) and evt.dir=< and
9 fd.l4proto != tcp and fd.connected=false and fd.name_changed=true)) and
10 (fd.typechar = 4 or fd.typechar = 6) and
11 (fd.ip != "0.0.0.0" and fd.net != "127.0.0.0/8" and not fd.snet in (rfc_1918_addresses)) and
12 (evt.rawres >= 0 or evt.res = EINPROGRESS))
Essa Macro:
- Verifica se é um evento do tipo connect (conexão de rede) do tipo saída (
evt.dir=<) - OU se é um evento do tipo sendto, sendmsg (conexão via socket de arquivo) do tipo saída, que o protocólo não seja TCP, o filedescriptor não esteja conectado e o nome mude, tipicamente de conexões UDP
- Caso alguma das condições acima seja verdadeira, e o tipo do file descriptor seja 4 ou 6 (IPv4 ou IPv6)
- E o IP não seja igual a 0.0.0.0 E a rede não seja igual a 127.0.0.0/8 (conexão ao localhost) E a rede de destino (
fd.snet) não esteja na listarfc_1918_addresses - E o evento tenha retorno maior que zero ou esteja ‘Em andamento’
Difícil? Na verdade, jogue essa expressão no vscode, e vá trabalhando ela através da abertura e fechamento de parenteses. Todos os campos existentes aqui estão muito bem explicados em Campos suportados
Porém, a macro acima não nos atende, pois filtra a saída para redes internas (rfc1918), o que é o caso da maioria das empresas. Vamos definir então o nosso conjunto macro/regra:
1- macro: outbound_corp
2 condition: >
3 (((evt.type = connect and evt.dir=<) or
4 (evt.type in (sendto,sendmsg) and evt.dir=< and
5 fd.l4proto != tcp and fd.connected=false and fd.name_changed=true)) and
6 (fd.typechar = 4 or fd.typechar = 6) and
7 (fd.ip != "0.0.0.0" and fd.net != "127.0.0.0/8") and
8 (evt.rawres >= 0 or evt.res = EINPROGRESS))
9
10- list: k8s_not_monitored
11 items: ['"green"', '"blue"']
12
13- rule: kubernetes outbound connection
14 desc: A pod in namespace attempted to connect to the outer world
15 condition: outbound_corp and k8s.ns.name != "" and not k8s.ns.label.network in (k8s_not_monitored)
16 output: "Outbound network traffic connection from a Pod: (pod=%k8s.pod.name namespace=%k8s.ns.name srcip=%fd.cip dstip=%fd.sip dstport=%fd.sport proto=%fd.l4proto procname=%proc.name)"
17 priority: WARNING
A regra acima:
- Cria uma macro
outbound_corppara qualquer conexão saindo - Cria uma lista
k8s_not_monitoredcom os valoresblueegreen - Cria uma regra que verifica:
- Se é tráfego saindo definido na macro
outbound_corp - E se tem o campo k8s.ns.name definido (o que significa que está executando dentro do Kubernetes)
- E se o namespace NÃO TEM uma label chamada
networkcom algum dos valores que está na listak8s_not_monitored. Se tiver, o tráfego não será monitorado
- Se é tráfego saindo definido na macro
Se essa regra for acionada, a seguinte saída será gerada:
1Outbound network traffic connection from a Pod: (pod=nginx namespace=testkatz srcip=172.16.204.12 dstip=192.168.0.1 dstport=80 proto=tcp procname=curl)
Aplicando as regras
O Helm chart nos permite instalar regras customizadas sem muito esforço.
Para fazer isso, nos pegamos as regras acima e colocamos dentro de uma estrutura customRules em um yaml, antes de atualizarmos a instalação:
1customRules:
2 rules-networking.yaml: |-
3 - macro: outbound_corp
4 condition: >
5 (((evt.type = connect and evt.dir=<) or
6 (evt.type in (sendto,sendmsg) and evt.dir=< and
7 fd.l4proto != tcp and fd.connected=false and fd.name_changed=true)) and
8 (fd.typechar = 4 or fd.typechar = 6) and
9 (fd.ip != "0.0.0.0" and fd.net != "127.0.0.0/8") and
10 (evt.rawres >= 0 or evt.res = EINPROGRESS))
11 - list: k8s_not_monitored
12 items: ['"green"', '"blue"']
13 - rule: kubernetes outbound connection
14 desc: A pod in namespace attempted to connect to the outer world
15 condition: outbound_corp and k8s.ns.name != "" and not k8s.ns.label.network in (k8s_not_monitored)
16 output: "Outbound network traffic connection from a Pod: (pod=%k8s.pod.name namespace=%k8s.ns.name srcip=%fd.cip dstip=%fd.sip dstport=%fd.sport proto=%fd.l4proto procname=%proc.name)"
17 priority: WARNING
É exatamente a mesma regra explicada acima, mas dentro de um campo customRules.rules-networking.yaml.
Após isso, nós atualizamos a instalação do Falco com o seguinte comando:
1helm upgrade falco falcosecurity/falco --namespace falco --set falcosidekick.enabled=true --set falcosidekick.webui.enabled=true --set ebpf.enabled=true -f custom-rules.yaml
Os Pods do Falco irão reiniciar. Se o Pod estiver em status de Error, veja o log deles que podem indicar alguma falha na regra (lembre-se, é um YAML, erros com espaços acontecem MUITO!)
Mostre-me os Logs!!
Executando um kubectl logs -n falco -l app=falco veremos que nossos logs já estão aparecendo:
1{
2 "output":"18:05:13.045457220: Warning Outbound network traffic connection from a Pod: (pod=falco-l8xmm namespace=falco srcip=192.168.0.150 dstip=192.168.0.11 dstport=2801 proto=tcp procname=falco) k8s.ns=falco k8s.pod=falco-l8xmm container=cb86ca8afdaa",
3 "priority":"Warning",
4 "rule":"kubernetes outbound connection",
5 "time":"2021-04-16T18:05:13.045457220Z",
6 "output_fields":
7 {
8 "container.id":"cb86ca8afdaa",
9 "evt.time":1618596313045457220,
10 "fd.cip":"192.168.0.150",
11 "fd.l4proto":"tcp",
12 "fd.sip":"192.168.0.11",
13 "fd.sport":2801,
14 "k8s.ns.name":"falco",
15 "k8s.pod.name":"falco-l8xmm"
16 }
17}
Mas esses são os Logs do próprio Falco, que não nos interessam. Vamos então marcar o namespace com a label que fará parar de gerar logs do tráfego dos Pods do Falco:
1kubectl label ns falco network=green
Show, agora que os Pods do Falco não entram nos logs de monitoração, vamos fazer uns testes :D Para isso eu criei um namespace chamado testkatz com alguns Pods dentro, e irei gerar um pouco de tráfego de saída:
1"output":"18:11:04.365837060: Warning Outbound network traffic connection from a Pod: (pod=nginx-6799fc88d8-996gz namespace=testkatz srcip=172.16.166.174 dstip=10.96.0.10 dstport=53 proto=udp procname=curl)
2=====
3"output":"18:11:04.406290360: Warning Outbound network traffic connection from a Pod: (pod=nginx-6799fc88d8-996gz namespace=testkatz srcip=172.16.166.174 dstip=172.217.30.164 dstport=80 proto=tcp procname=curl)
No log acima, podemos ver a chamada ao DNS, e em seguida a chamada ao servidor de destino. Vemos inclusive que o programa que fez essas chamadas foi o curl rodando dentro do container.
Visualizando de forma melhorada
Ninguém merece ficar vendo logs JSON rodando na tela, certo? Entra em ação aqui o Falco Sidekick. Ele foi instalado no começo, então a configuração que precisamos fazer é para que ele envie esses “alertas” para algum lugar desejado.
O sidekick vem com uma interface Web, que pode ser acessada via port-forward, por exemplo:
1kubectl port-forward -n falco pod/falco-falcosidekick-ui-764f5f469f-njppj 2802
Após isso, basta acessar o browser local através do endereço [http://localhost:2802/ui] e você terá algo tão legal quanto:
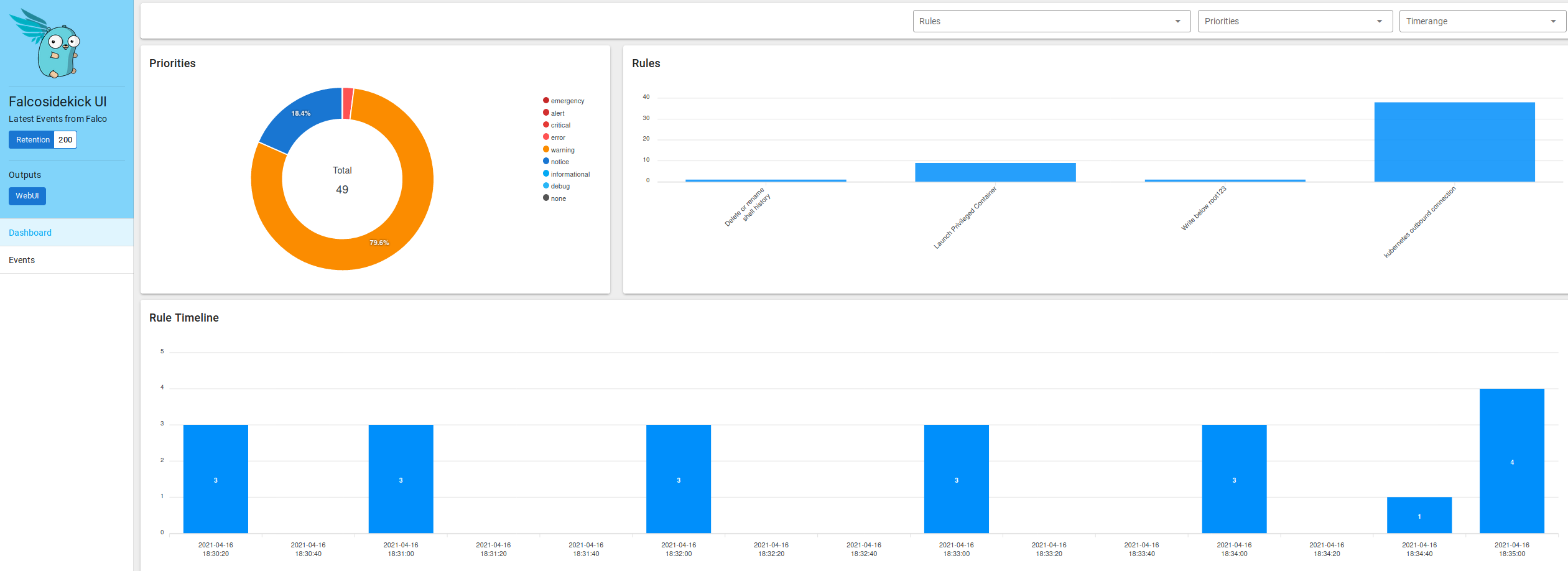
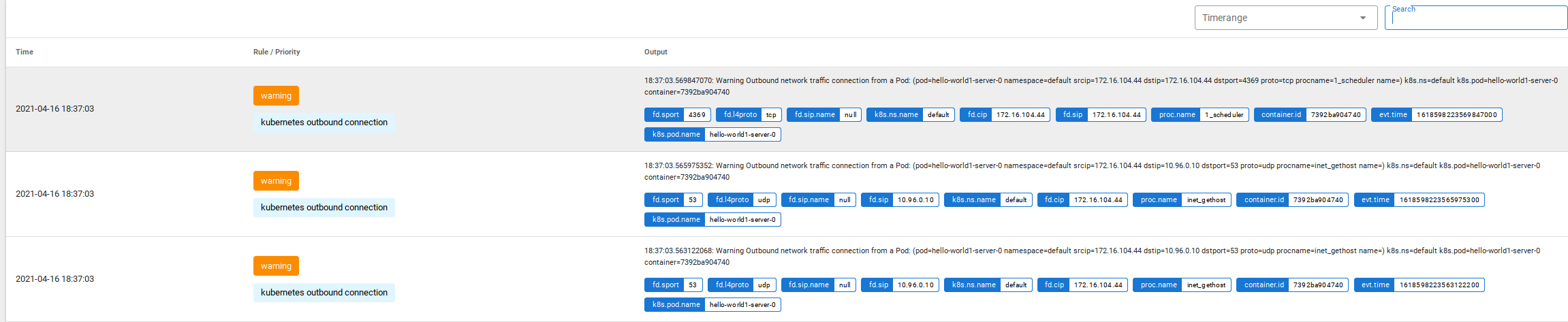
Mas isso não gera retenção. Vamos então configurar o Sidekick para apontar para um Grafana Loki. Pode-se usar o freetier do Grafana Cloud, por exemplo. Gere uma URL, User e API Key no dashboard do Grafana, e adicione as informações na instalação do Sidekick conforme a seguir (obrigado Thomas Labarussias pela ideia!):
1helm upgrade falco falcosecurity/falco --namespace falco --set falcosidekick.enabled=true --set falcosidekick.webui.enabled=true --set ebpf.enabled=true --set falcosidekick.config.loki.hostport=https://USER:APIKEY@logs-prod-us-central1.grafana.net -f custom-rules.yaml
Reinicie o sidekick com kubectl delete pods -n falco -l app.kubernetes.io/name=falcosidekick e então você passará a ver mensagens [INFO] : Loki - Post OK (204) no log do sidekick cada vez que um alerta for disparado.
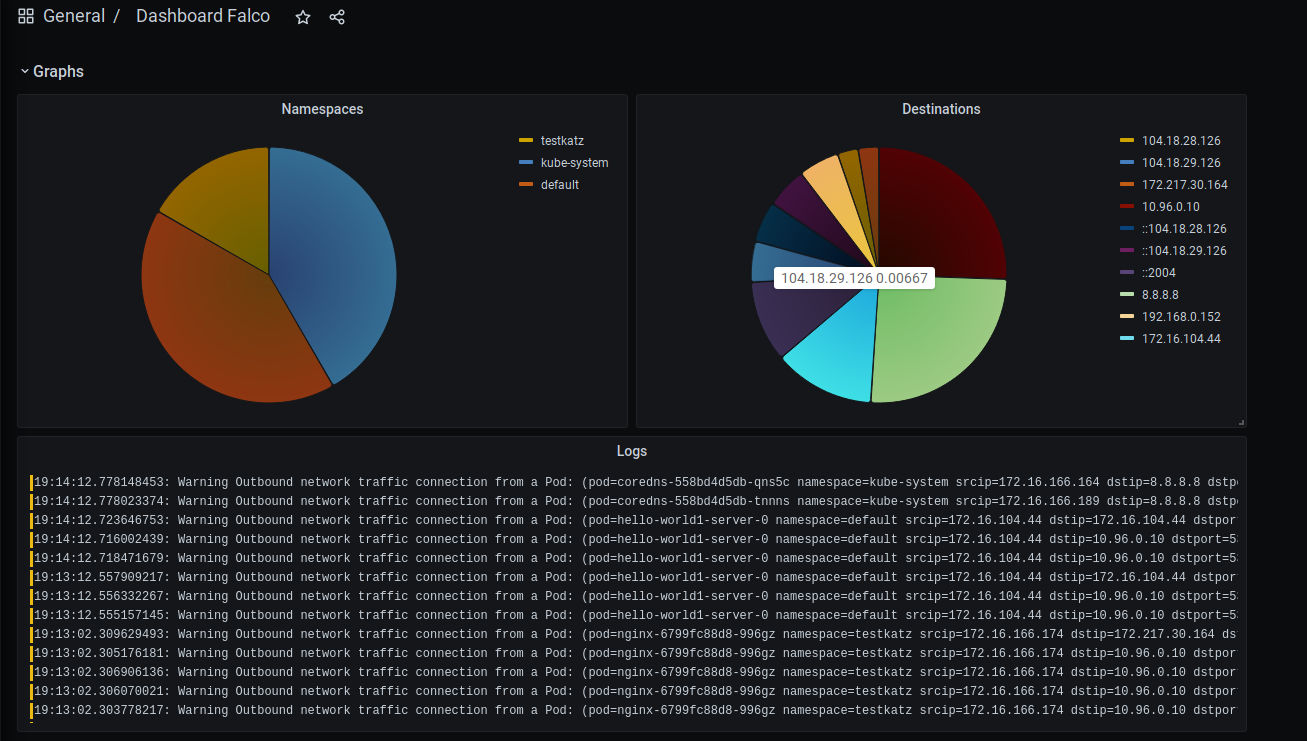
Com isso, no Grafana Cloud você conseguirá ter um dashboard parecido com o que mostrei acima :)
Eu deixei meu exemplo de dashboard aqui mas lembre-se de alterar para o seu datasource do Loki e, caso você tenha melhorado o dashboard, não deixe de postar e mandar uma foto :D